JPA 영속성 컨텍스트의 장점

JPA에서 영속성 컨텍스트를 사용함으로서 얻을 수 있는 장점에 대해서 알아봅시다
영속성 컨텍스트가 가지는 장점을 이해하기 위해서는 먼저 영속성 컨텍스트가 가지고 있는 특성을 알아봐야 합니다.
특징
영속성 컨텍스트는 여러 특징들을 가지고 있습니다.
1. key-value 형식으로 엔티티를 관리한다
영속성 컨텍스트는 영속화된 엔티티를 Map자료구조 와 같이 key-value 형식으로 저장합니다. 저장한다는 표현보다는 캐싱한다는 표현이 더 정확하겠군요!
그러면 key와 value에는 각각 어떤 정보들이 들어갈까요??
key에는 해당 엔티티를 식별할 수 있는 식별자 값이 들어갑니다. 쉽게 말해 ID죠
영속성 컨텍스트는 DB의 기본 키를 key로 사용합니다. @Id 가 붙은 필드가 아이디로 사용되겠군요!!
value 에는 엔티티가 들어갑니다.
그리고 이렇게 데이터를 해주는 Map 형태의 캐시의 이름을 1차 캐시 라고 합니다!
2. 영속성 컨텍스트 - DB
영속성 컨텍스트 내부에 데이터가 어떻게 캐시되는지는 간단하게 위에서 살펴봤습니다. 그러면 캐시가 아닌 실제 DB에 저장은 언제 하는 것 일까요???
바로 flush 될 때입니다. 트랜잭션이 commit 되는 순간 영속성 컨텍스트에 새로 저장된 데이터를 DB에 반영하는데, 이를 flush 라고 합니다!!
여러 장점들
영속성 컨텍스트가 위의 특징들을 가지고 엔티티르 관리하면 다음과 같은 장점들을 얻을 수 있습니다
- 1차 캐시
- 동일성 보장
- 트랜잭션을 지원하는 쓰기 지연
- 변경 감지
- 지연 로딩
오늘 알아볼 여러 장점들인데 하나 하나 알아보도록 합시다!!
저는 DB ID 전략은 AUTO_INCREMENT로 설정했기 때문에 트랜잭션이 커밋되기 전에 persist만 해도 쿼리문이 날아갑니다. 로그를 보실 때, 유의 바랍니다!
1차 캐시
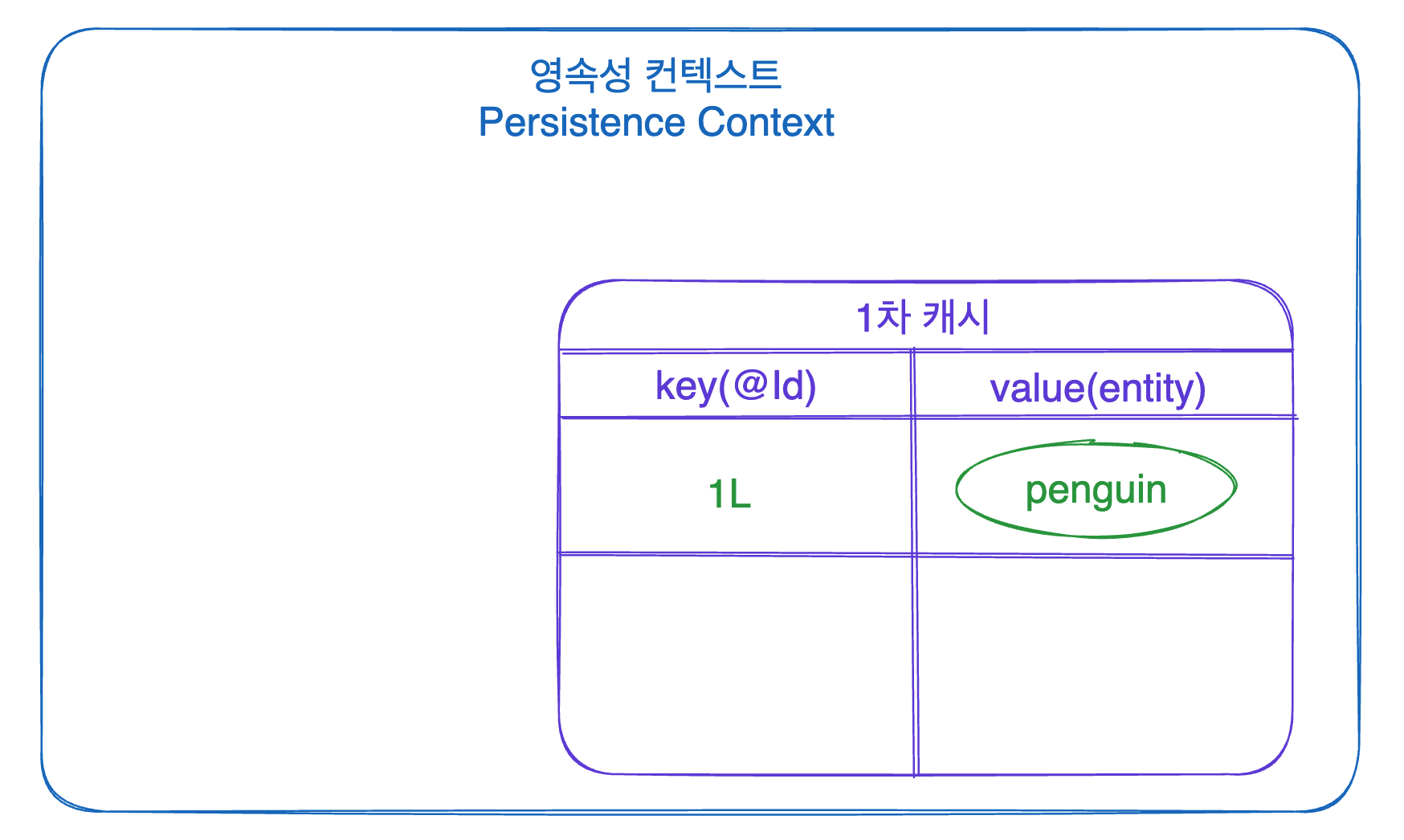
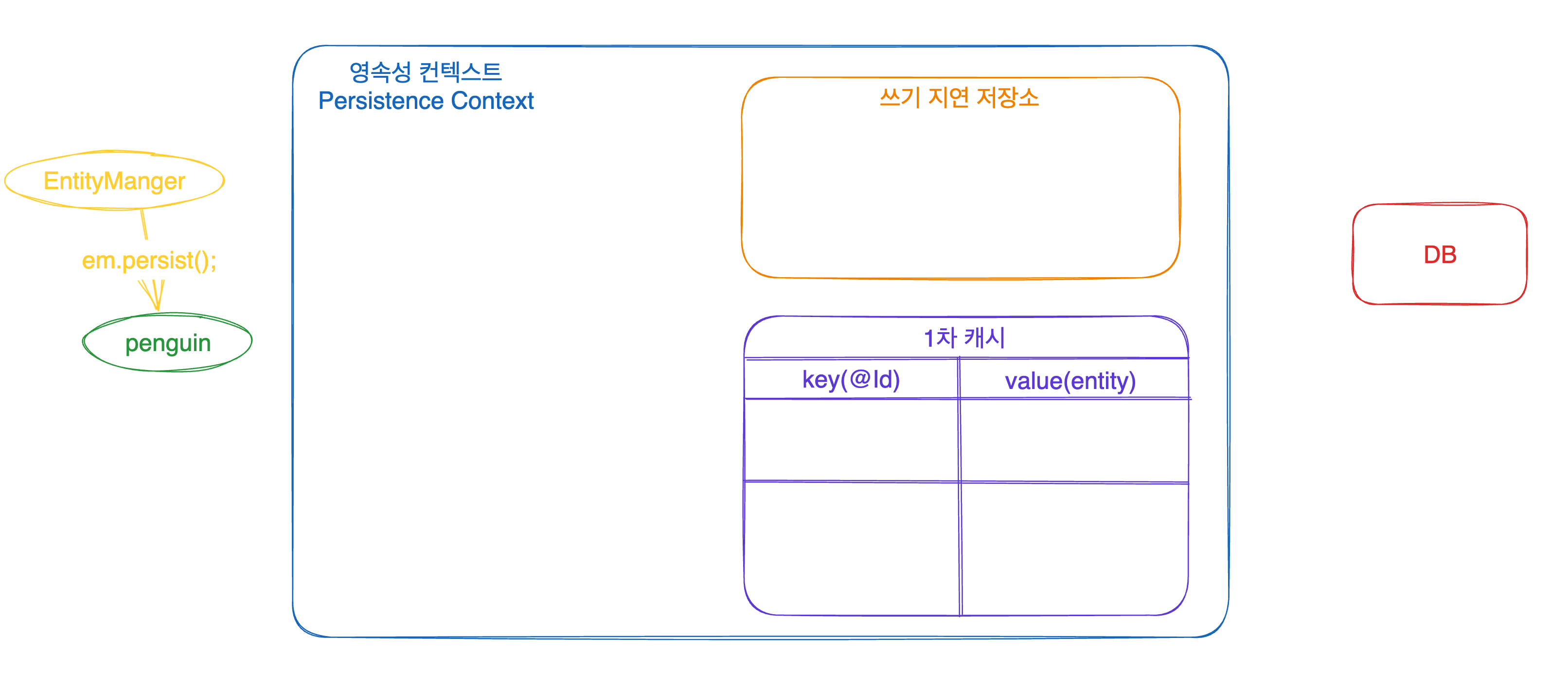
1차 캐시는 위에서 말했던 영속성 컨텍스트가 관리 중인 엔티티들(영속 상태의 엔티티들)을 저장한 캐시입니다!!
em.persist(penguin)
전 게시물에서 생성을 했었던 비영속 상태의 penguin이 위의 코드로 영속화 되었다고 해 봅시다 그러면 penguin은 그림과 같이 1차 캐시에 저장되게 됩니다
그럼 이렇게 저장해서 우리가 어떻게 활용할 수 있을까요??
1. 조회
먼저 조회할 때 사용이 가능합니다 캐시라는 것이 익히 알다시피 데이터를 특정한 장소에 저장해놔서 병목현상을 해결할 수도 있고(ex 메모리와 디스크의 속도 차이), 최근에 조회했거나 자주 조회했던 정보를 저장해서 DB를 굳이 찌를 필요 없이 캐시된 데이터를 리턴함으로서 성능 상의 이점을 얻게 헤주는 (ex Redis) 역할을 수행해 주는 아이입니다.
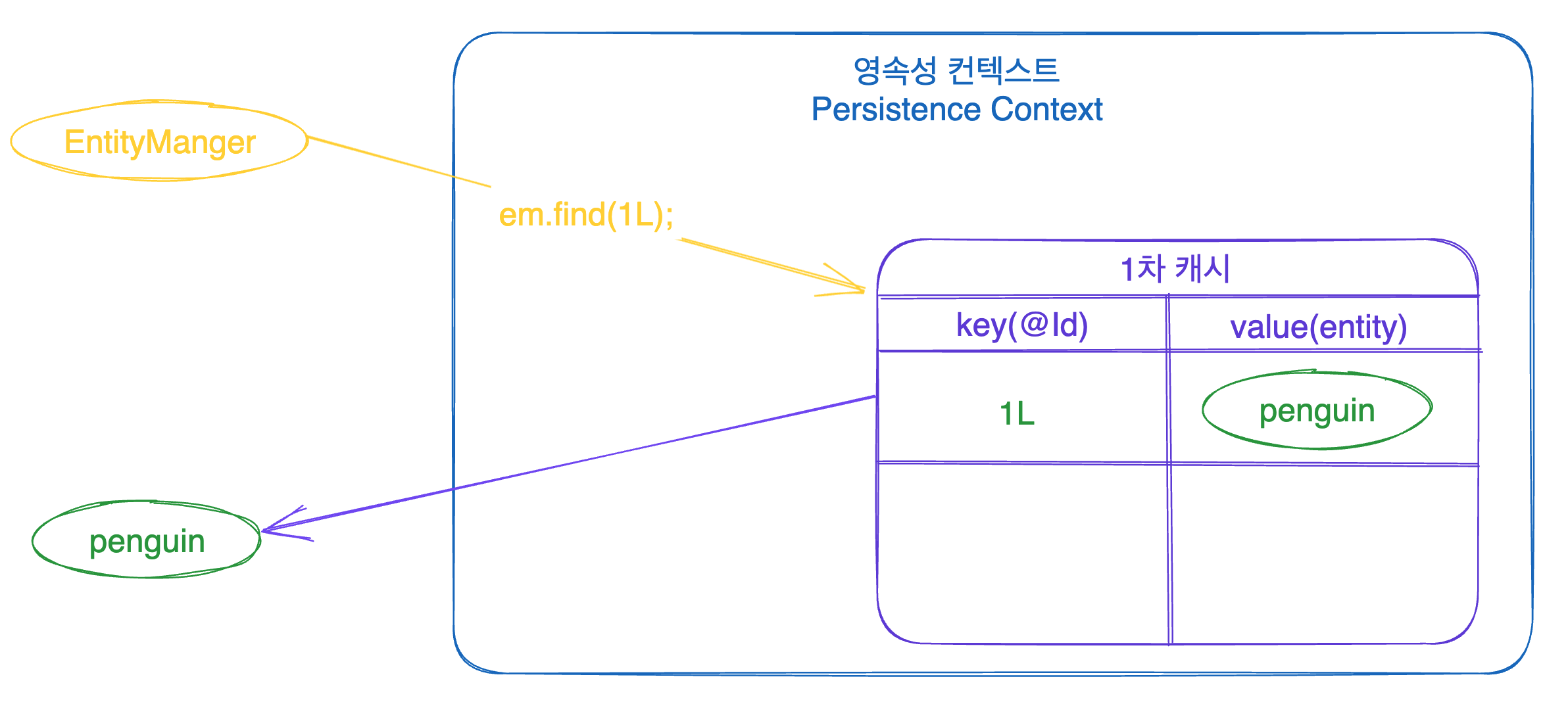
EntityManager 가 특정 데이터를 조회하고자 할 때, EntityManager 는 무작정 DB에서 데이터를 찾지 않습니다. 1차 캐시에 해당 데이터가 있는지 먼저 확인을 하죠! 그리고 1차 캐시에 저장된 데이터가 있으면 해당 데이터를 리턴하고, 없으면 DB를 찔러서 가져옵니다. 데이터를 가져오는데 성공하면 해당 데이터를 1차 캐시에 저장하고 해당 데이터를 리턴해줍니다.
em.find

상황 1 1차 캐시에 찾는 데이터가 있는 경우 cache hit
상황 2 1차 캐시에 데이터가 없어서 DB를 갔다오는 경우 cache miss 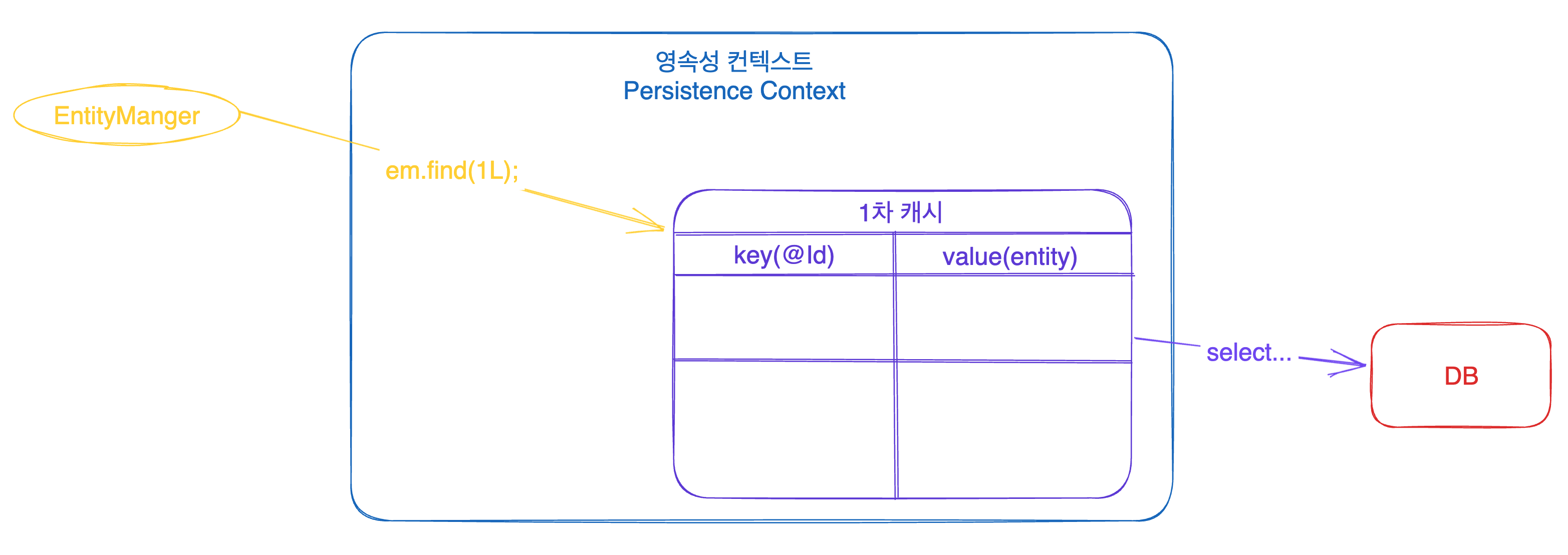
어 없네…
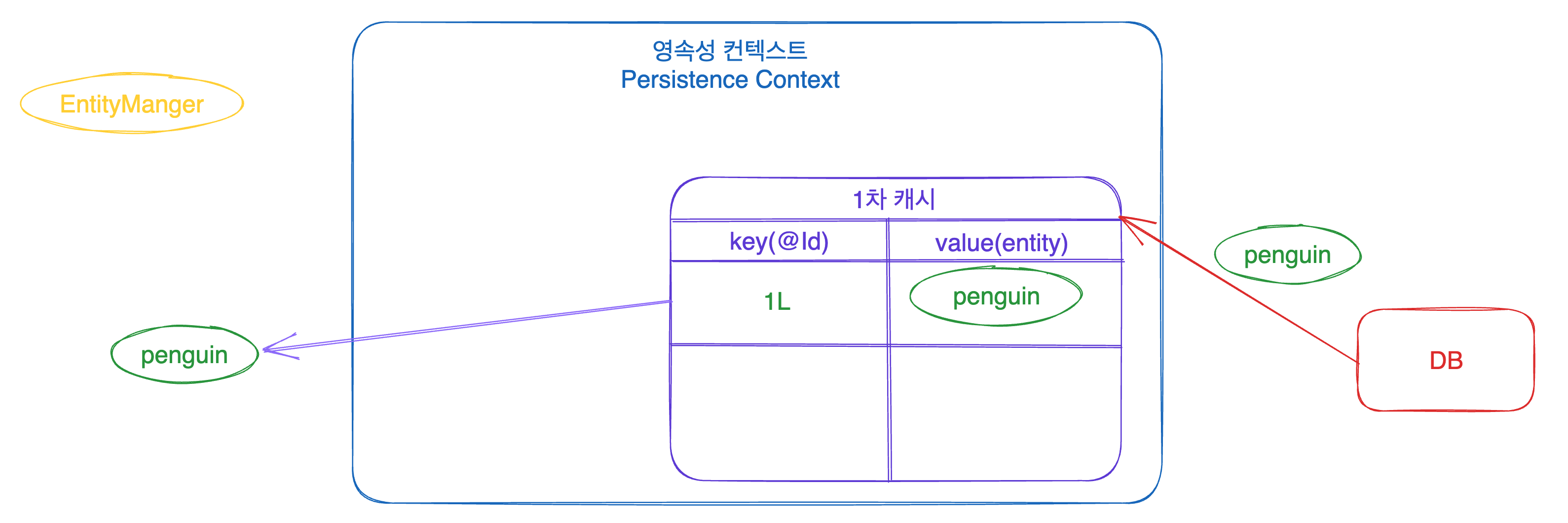
오다 주웠다(??)
코드로 보면 아래와 같습니다
펭귄을 하나 만들고 나서, 영속화 한 다음 데이터를 2번 조회할 것입니다!! 그러면 각각 데이터를 어디서 가져올지 확인하는 코드입니다!
@Test
void findTest(){
EntityManager em = emf.createEntityManager();
EntityTransaction transaction = em.getTransaction();
transaction.begin(); // 트랜잭션 시작
log.info("핑구 데이터 생성 - 비영속");
Penguin penguin = Penguin.builder()
.age(3) // id 값은 DB에서 자동 생성하므로 넣으면 안됨!
.length(140)
.name("핑구")
.species(Species.EMPEROR_PENGUINS)
.weight(30)
.build();
log.info("핑구 데이터 persist - 영속");
em.persist(penguin); // 핑구 영속화
transaction.commit(); // 트랜잭션 종료
em.clear(); // 영속성 컨텍스트 초기화
// 핑구 찾기
log.info("초기화 된 영속성 컨텍스트에서 데이터 찾기 -> DB 조회");
Penguin findPenguin1 = em.find(Penguin.class, 1L);
log.info("한 번 찾은 데이터 다시 찾기 -> 1차캐시에 저장된 데이터 조회");
em.find(Penguin.class, 1L);
}
로그
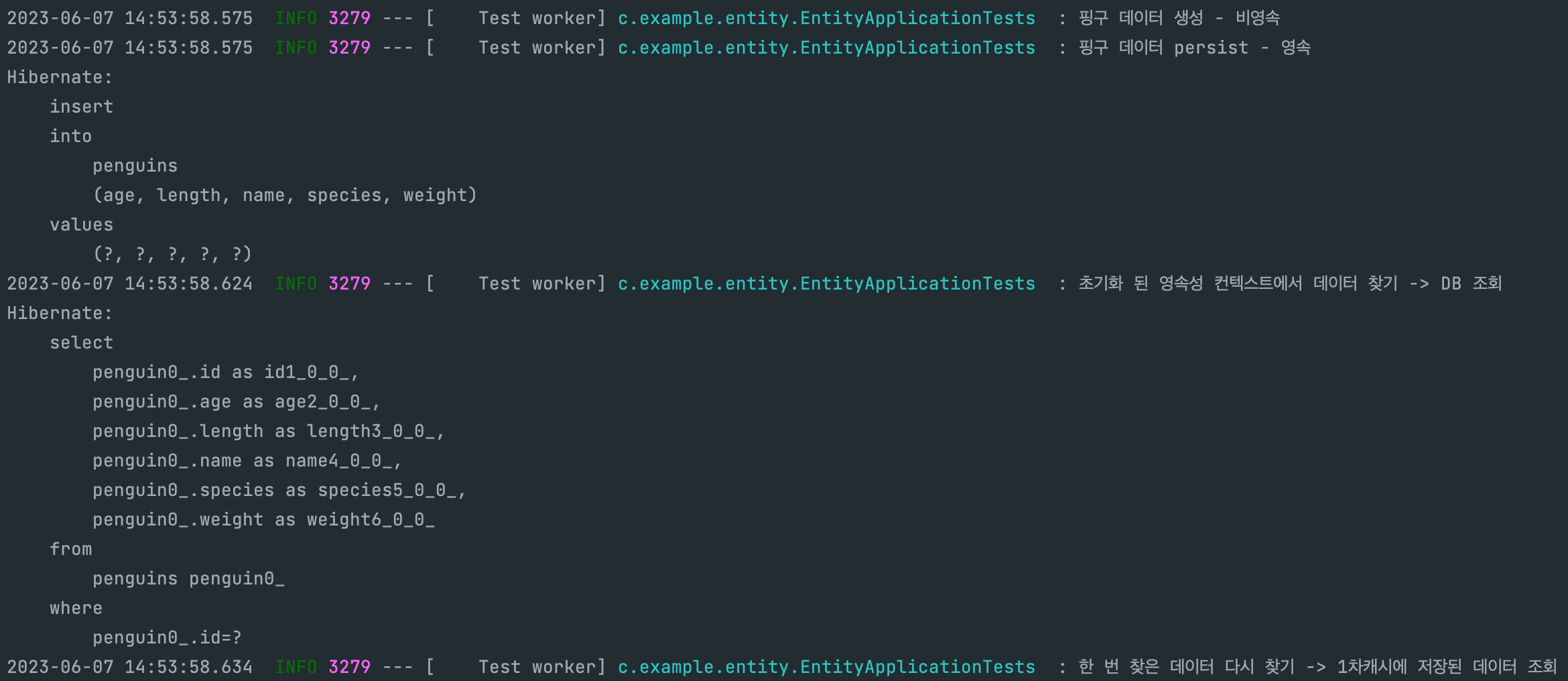
위에서 보시다 시피 영속성 컨텍스트가 초기화 된 후 처음 펭귄을 조회하면 영속성 컨텍스트 안에는 해당 데이터가 존재하지 않으므로 DB에 SQL을 날려서 직접 확인하는 모습을 볼 수 있습니다
하지만 두 번째 조회할 때는 아까 DB에서 가져온 데이터를 이미 1차 캐시 안에 넣어놨으므로 DB를 찌르지 않는 모습을 볼 수 있습니다
동일성 보장
그럼 여기서 생기는 의문점이 하나 있습니다. 두 번 데이터를 가져왔는데… 이 두 객체는 같은 객체일까요?? 아니 정확히 말해서 같은 주솟값을 가지는 데이터일까요?? 아니면 1차 캐시에 저장된 데이터를 복사해온 2개의 각자 다른 데이터일까요??
@Test
void isEqual(){
EntityManager em = emf.createEntityManager();
EntityTransaction transaction = em.getTransaction(); // 트랜잭션 시작
transaction.begin(); // 트랜잭션 시작
log.info("핑구 데이터 생성 - 비영속");
Penguin penguin = Penguin.builder()
.age(3)
.length(140)
.name("핑구")
.species(Species.EMPEROR_PENGUINS)
.weight(30)
.build();
log.info("핑구 데이터 persist - 영속");
em.persist(penguin); // 핑구 영속화
transaction.commit(); // 트랜잭션 종료
log.info("펭귄 2번 찾기");
Penguin findPenguin1 = em.find(Penguin.class, 1L);
Penguin findPenguin2 = em.find(Penguin.class, 1L);
log.info("두 펭귄은 같은 펭귄인가요??? : {}", findPenguin1 == findPenguin2);
}
로그

보시면 같은 객체가 리턴된 것을 확인할 수 있습니다.
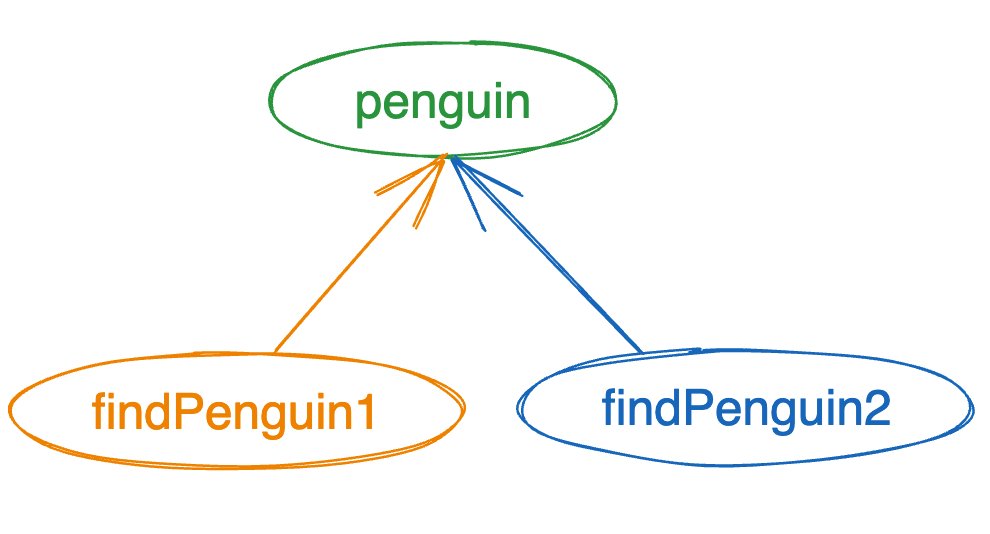
위 그림과 같이 두 펭귄의 객체 이름은 다르지만 사실상 같은 객체를 가리키고 있기 때문에 같다고 봐도 무방할 것 같습니다.
더 자세한 설명으로는 동일성 vs 동등성 에 대한 설명이 필요하지만… 여기는 해당 키워드를 자세히 다룰 예정이 아니므로 넘어가도록 하겠습니다.
쓰기 지연
2. 등록
데이터가 1차 캐시에 저장되는 것은 DB에 저장된 다는 것과 같은 의미일까요?? 당연히 아닙니다!!
그냥 말 그대로 캐시일 뿐이죠
DB에 데이터를 실제로 넣으려면 쿼리 문을 날려야 하는데 누가 날릴까요??
쓰기 지연 저장소
바로 쓰기 지연 저장소에서 실질적으로 DB로 쿼리를 날립니다. 그러면 저장소에 SQL은 언제 쌓이고, 언제 날리는 걸까요??
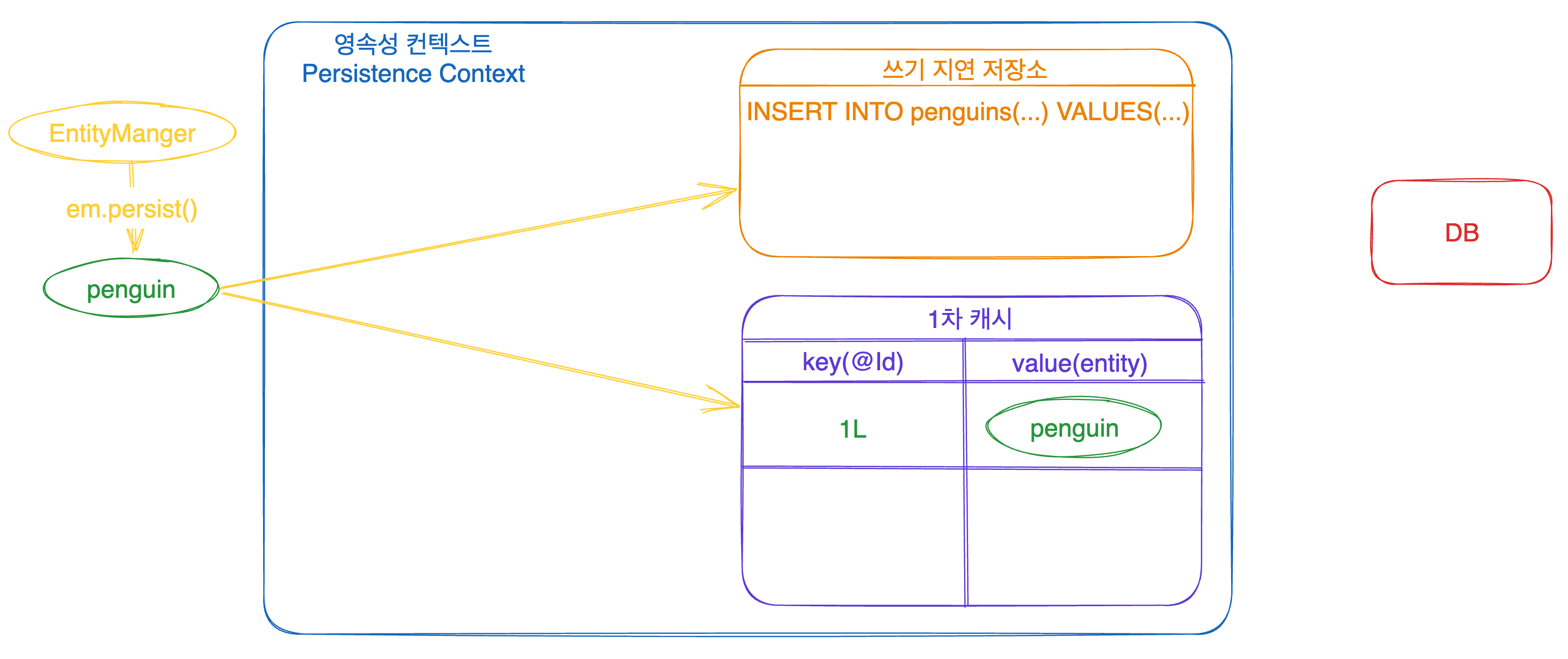
이렇게 persist를 하게 되면 1차 캐기에 엔티티가 저장됨과 동시에 쓰기지연 저장소에 SQL이 저장되게 됩니다. 이렇게 당장은 날리지 않고 트랜잭션 안에서 차곡차곡 쌓아놓죠!!
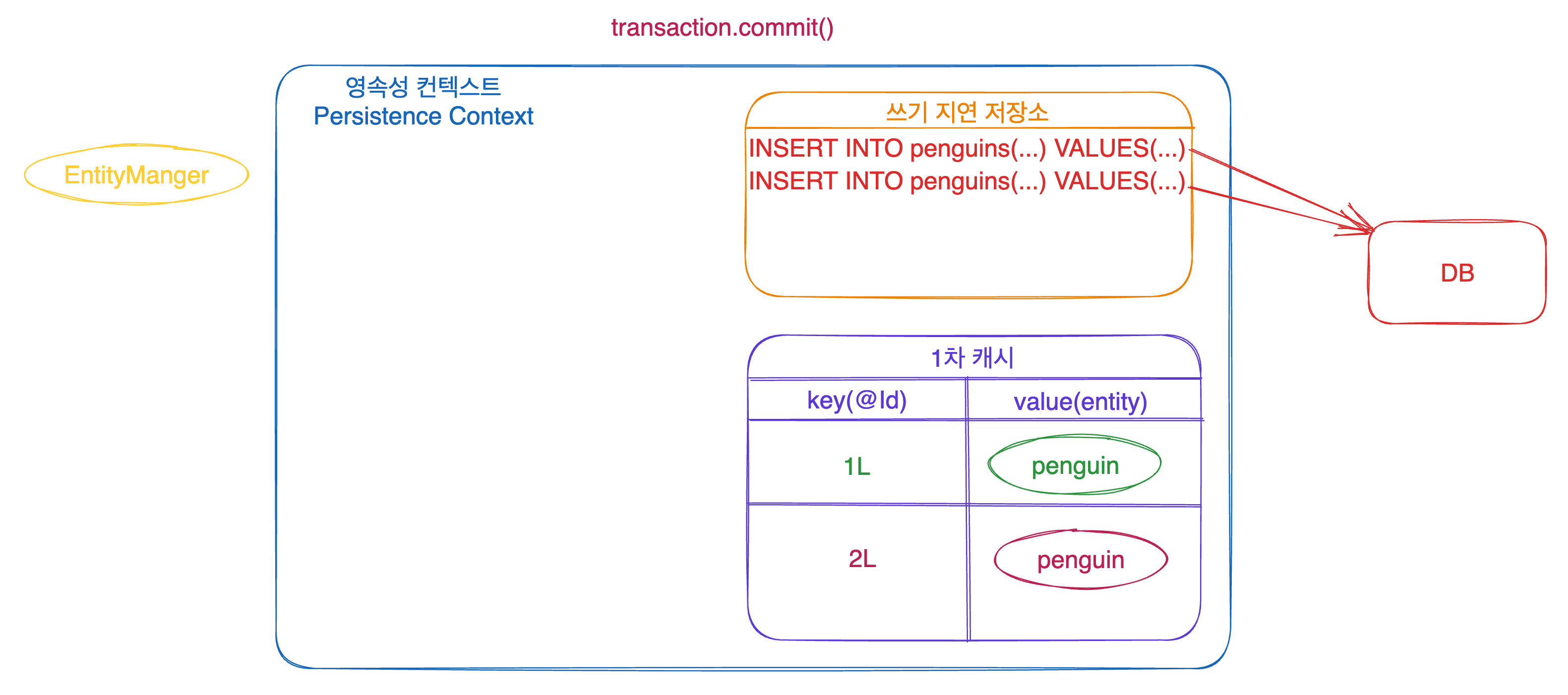
이렇게 쌓인 쿼리문들은 대개 트랜잭션이 종료될 경우 DB에 반영되게 됩니다!! 트랜잭션이 commit 되면, 영속성 컨텍스트는 flush 를 수행하고 해당 작업 수행시 쓰기 지연 저장소에 저장된 쿼리문들이 나가게 됩니다!!
이렇게 즉시 반영되는 것이 아니라 commit, flush 될 때 까지 대기하기 때문에 쓰기 지연 저장소라는 이름이 붙은 거죠!
그렇다면 굳이 왜 즉시 쿼리문을 날리지 않고 별도의 저장소에 저장을 해놓고 나중에 날리는 것일까요??
변경 감지
그렇다면 엔티티의 수정은 어떻게 할까요?? 사실 1차 캐시는 엔티티 자체만을 저장하는 것이 아니라 초기 엔티티의 스냅샷을 저장합니다.
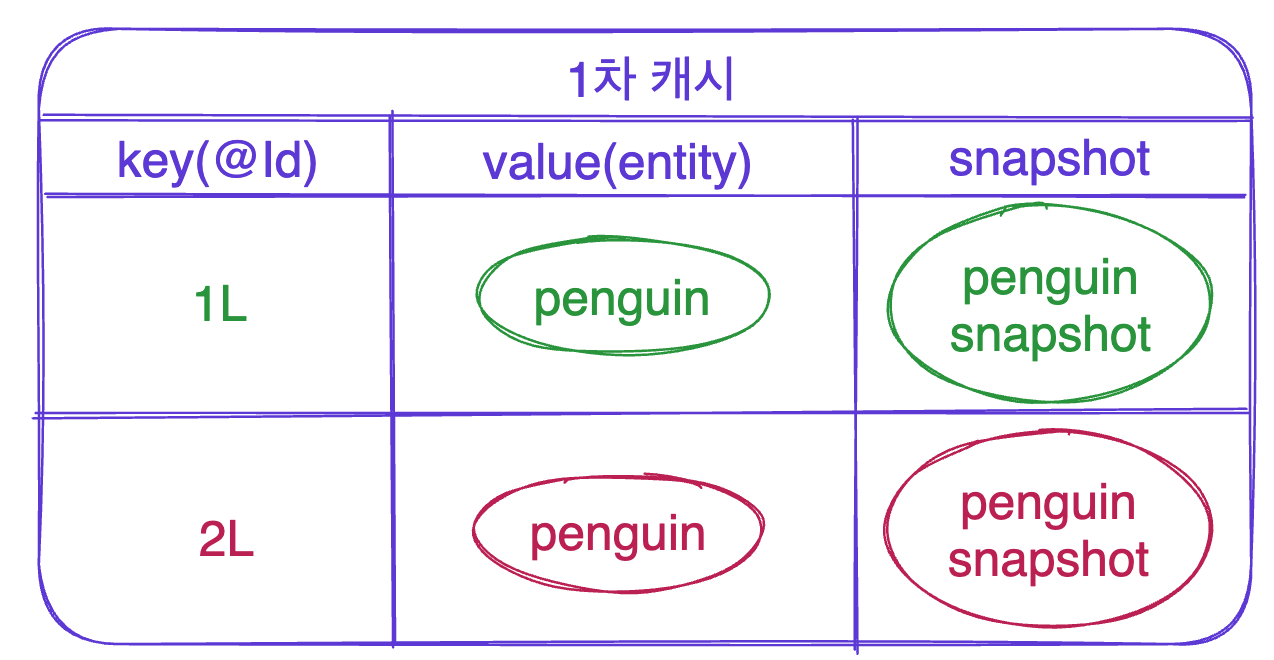
1차 캐시는 엔티티의 초기 상태의 형상을 저장해놓는다.
그렇기 때문에 setter 메소드 및 각종 비즈니스 로직의 수행으로 value에 저장된 객체의 값이 스냅샷과는 다를 때(엔티티의 값이 수정될 경우), 이를 감지할 수 있습니다.
그리고 이를 변경 감지라고 합니다
영속성 컨텍스트가 엔티티의 변경을 감지하면, 적절한 쿼리문을 생성해 쓰기 지연 저장소에 쿼리문을 적재합니다.
그러면 언제 변경을 감지하고 쿼리문을 적재할까요??
바로 flush, commit 될 때입니다!!
그림으로 확인해보면 아래와 같습니다!

참고로 변경 감지는 영속 상태의 엔티티만 가능합니다!!
한 번 간단한 테스트를 돌려서 확인해보겠습니다
@Test
void updateWithDirtyChecking(){
EntityManager em = emf.createEntityManager();
EntityTransaction transaction = em.getTransaction(); // 트랜잭션 시작
transaction.begin(); // 트랜잭션 시작
log.info("핑구 데이터 생성 - 비영속");
Penguin penguin = Penguin.builder()
.age(3)
.length(140)
.name("핑구")
.species(Species.EMPEROR_PENGUINS)
.weight(30)
.build();
log.info("핑구 데이터 persist - 영속, DB 정책이 IDENTITY 라 바로 날아감");
em.persist(penguin); // 핑구 영속화
log.info("핑구 나이 1 증가");
penguin.setAge(4);
log.info("트랜잭션 커밋");
transaction.commit();// 트랜잭션 종료
em.close();
}
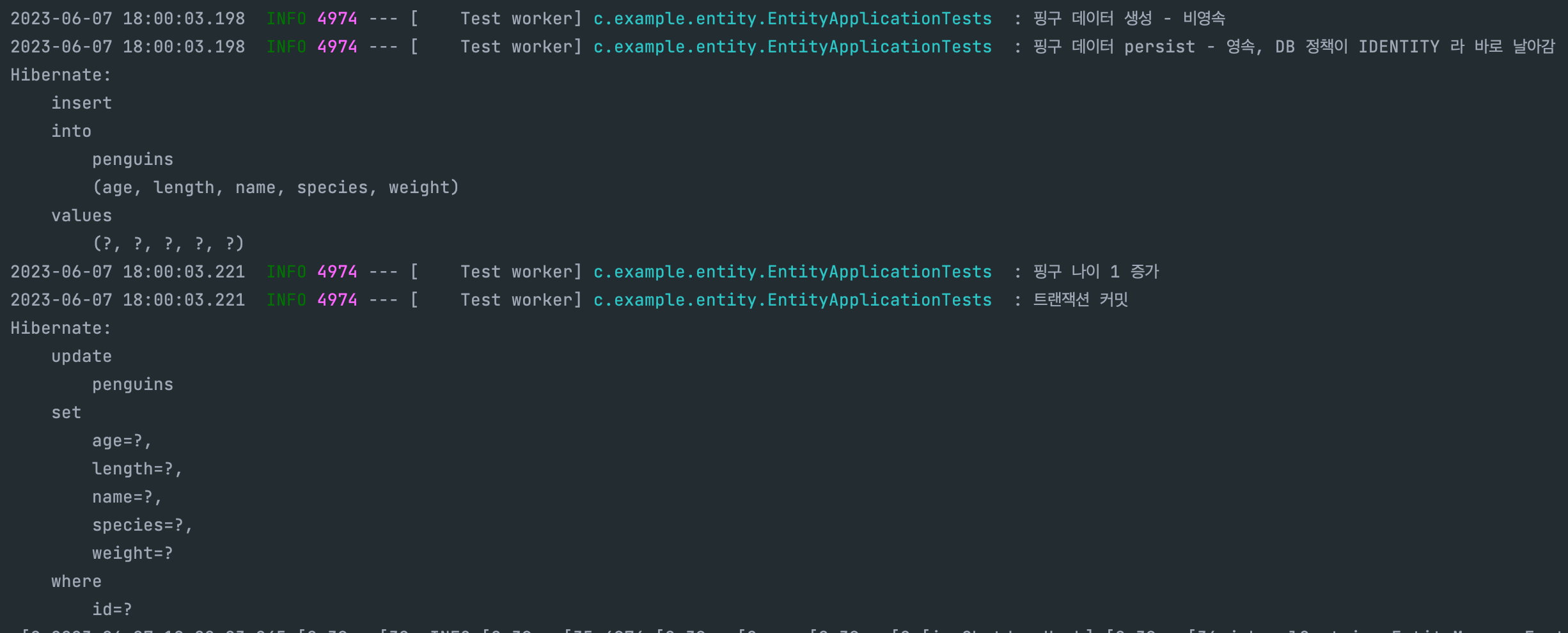
영속화만 제대로 했는데 알아서 수정 쿼리문 까지 날려주는군요!!
그런데 저는 나이 필드 하나만 수정했는데, 모든 필드를 수정하는 쿼리 문이 날아가는 것을 보실 수 있습니다!!
이렇게 되면 쿼리문이 길어져서 데이터 전송량이 많아지지 만, 다음 두 가지 측면에서 이득을 볼 수 있습니다.
- 수정 시 항상 동일한 쿼리문을 내보내면 되기 때문에, 쿼리 재사용이 가능하다.
- DB는 동일한 쿼리를 받으면 이전에 파싱된 쿼리를 재사용할 수 있다.
마무리
오늘은 영속성 컨텍스트를 사용하면 얻을 수 있는 이점에 대해서 알아봤습니다 두서 없는 글 읽어주셔서 감사합니다!!
